 |
The Effects of Congruency Between Structural & Contextual Dominance in Image Processing |
|
The Effects of Congruency Between Structural & Contextual Dominance in Image Processing |
In an instructional message there are often subtle, yet critical, aspects that must also be emphasized in supportive graphics or images. The instructional designer must be able to describe the contextual emphasis such that an artist or graphic designer will be able to manipulate the structural elements of the picture in a corresponding fashion. The goal is to make the structural emphasis congruent with the contextual emphasis. The emphasis of the contextual message and the emphasis of the structure of a picture is referred to in this paper as contextual dominance and structural dominance respectively.
In an instructional message the contextual dominance is most often conveyed in the form of printed or spoken sentences. Within any sentence used in conjunction with a picture are nouns or phrases that directly relate to contextual elements within the picture. For instance if we are presented a picture and heard "The man walked through the door." we would expect to identify a man and a door in the picture. Both "man" and "door" may be called referents in the sentence since they refer to objects perceptible in the picture. The study described herein varied the dominance of referents used in a number of sentences and compared the patterns of subsequent observations of 15 pictures. The goal was to identify structural and/or contextual elements that stimulated consistent patterns of observation. A brief discussion of the literature, the methodology used, results for two pictures, and a summary of conclusions follows.
Another attribute, which relates to complexity, is that of the "degree of realism" to which an image may be attributed. The "degree" represents a continuum from concrete, or realistic, to abstract, or non-realistic. Gavriel Salomon describes this continuum operationally in terms of the degree of "coding" one must do when encountering a visual representation of something.
"Certain representations appear to be more "realistic" because their symbolic form comes closer to the way users represent the depicted entity to themselves. The less recoding something requires, the mentally "easier" it is to experience and the more "real" it appears." (Salomon, 1981 pg. 201)
Relative to this "concrete to abstract continuum", concrete images are remembered better than abstract images (Paivio, 1983; Winn, 1982; Findahl & Hoijer, 1976; Wolf, 1970). On the other hand, abstract graphics have been found to be more successful in educational contexts due to fewer structural elements (Heuvelman, 1987).
"Little attempt was made to examine the design qualities of the picture itself or the component cues of the picture in terms of learning theory. All modes of pictorial representation were considered as infinitely large masses of stimuli and examined as such... no attention was given to isolating those elements which make an instructionally effective visual." (Nesbit, 1978 pg. 496)
The variable of style was of interest to Molner. He believed that traditional definitions of style, usually treated as purely affective and subjective, were identifiable in terms of structural attributes of an image. His eye movement study of Renaissance and Baroque paintings illustrates that the structural attributes of paintings may be utilized in such a stylistic manner that it can influence the viewer to scan an image at a certain speed and focus. He found that art of the Renaissance was viewed with large and slow eye movements, while Baroque art produced denser and shorter eye movements (Molner, 1981).
This strategic focus supports previous prescriptive conclusions relating to color, complexity, and the schematic design of an image. Both point to contextual cues dictating structural prescriptions in the visual channel and specific reliance on the verbal channel for being the major carrier of contextual information.
Koroscik, Desmond, and Brandon examined this relationship among structural, semantic, and verbal contextual information. They began the study with the following hypotheses: It was speculated that the encoding and retention of art is subject to the type of contextual information given to viewers at presentation. Verbal labels with literal references to the objects, persons, or events depicted in an artwork ought to evoke semantic encodings that differ from those generated in response to verbal references pertaining to the work's expressive qualities and/or other non-literal aspects of the depicted content. (Koroscik, 1984 pg. 332)
By presenting first a verbal contextual cue and then presenting an image, they were able to measure the effect of the context on retention of the desired message. Since the contextual cues referred literally to structural elements within the images, some information was also gained about the degree of distraction of "non-pertinent" structural elements. Results also indicated that accurate interpretation of meaning was a function of the level of abstraction that characterized each artwork and of the type of contextual information given at input (Koroscik, 1984).
These results offer very few prescriptions to a message designer other than a sense that context and the structure of an image may somehow be interdependent. On one hand structural concerns are important for immediate interpretation and long-term memory, yet on the other there is, at some point, a shift of focus to contextual aspects of an image. Which is dominant, structure or context? What is the relationship between the abstract-to-concrete word continuum and an abstract-to-concrete image continuum? The concept of congruency begins to explore the relationships posed by these questions.
..thus the compositional structure affects perception most dramatically when structure and meaning are united within the same areas of the picture. (Marschalek, 1986 pg. 135)
This succinct statement encapsulates the idea of congruency between words and images. The concept of congruency between the structural components of an image and the context presented is of extreme importance to the message designer. Congruency deals with the basic problem of linking words and images together. Many researchers have found that when structural features and contextual features are congruent, then attention to the message is maximized (Heuvelman, 1987; Hsia, 1977; Marschalek, 1986; Miller, 1982; Nodine, 1982; Wember, 1976)
A growing number of cognitive scientists are specifically looking at the relationship between the cognitive processing of words and the processing of images. A Dual-Coding Theory was developed by Paivio which stated that:
"The verbalization of a picture's features increases the probability that two codes are activated in the formation of stimulus memories. The argument is that sensory features of pictures are stored in imagery codes, while the products of verbalization are retained as verbal or linguistic codes." (Madigan, 1982, pg. 80)
This statement is contrary to a "common code" view that says pictures somehow possess a faster access than words to a common conceptual system. The dual-coding view, on the other hand, sees picture-word latency differences as stemming from a time consuming translation from one symbolic code to another and that semantic information required in the decision task is typically stored nonverbally. Numbers of other researchers have been testing similar concepts and have arrived at some meaningful conclusions. Segal and Fusella (1970) found, by using interference tests, that cognitive processing is modality (visual or audio) specific, i.e., the brain operates with a separate processing system for each modality. Nugent (1982) and Wickens (1984) found that "learners process pictorial and linguistic information through functionally independent, though interconnected, cognitive systems."
Whenever one deals with issues of context, they are subject to personal interpretation as to their meaning, importance, and dominance. For an individual, attribution of meaning will depend on knowledge the viewer already has, knowledge that can be associated with the incoming information (Heuvelman, 1987). This view is commonly held by many researchers and recent language comprehension studies have indicated that language processing involves a context-dependent knowledge base that operates in an integrative and elaborative manner (Anderson & Ortony, 1975; Barclay, 1973; Bransford, Barclay, & Franks, 1972; Marschark & Pavio, 1977). Dillen (1983), Braden & Walker (1980) and Wise (1982) also point to prior knowledge of the individual as a variable which significantly determines how an image will be perceived. Craik and Lockhart place prior experience as a comparative referent within the memory storage system. These researchers go on to describe two stages of the memory formation process. They are:
Some researchers have consistently found that when images are utilized which include people, fixations center on their faces to the almost total exclusion of anything else in the image (Buswell, 1935; Chu & Schramm, 1975; Guba, et al, 1964; Yarbus, 1967). The implication of this is that people know from experience that faces and animate objects, in general, are primary providers of contextual information.
Animate objects receive a higher density of fixations than inanimate objects when both are contained in the same picture. When considering portraits, the highest density of fixations occurs on the eyes, nose, and mouth because these areas of the face tend to convey information concerning emotion and the degree of physical attractiveness of the individual. (Yarbus, 1967 pg. 28) Structural and Contextual Dominance
A primary concept within this study, in relation to the analysis of contextual and image structure, is that of dominance. It has been found that it is possible to define an image in terms of its physical structure apart from its contextual elements (Friedman & Polson, 1989; Koroscik, 1984; Marschalek, 1986). Likewise it is proposed that linguistic analysis can focus on both the structural aspects of a sentence apart from the contextual aspects (Mason, Kniseley, & Kendall, 1979; Smith & van Kleeck, 1986). In each of these four categories it is proposed that a dominance exists which may be utilized in comparing these categories, resulting in a description of congruence, non-congruence, or ambiguity. It is toward the definition of image structure, and specifically those structural elements which affect dominance, that this study is directed.
Since no models emerge from the literature, we may turn to the discipline of graphic design for a description of visual form by Wucius Wong (Wong, 1972, pg. 6) which seems to fit a hierarchical description of visual form. An adaptation of his hierarchy appears below.
In discussing the structural form of an image, the most appropriate discipline to draw from is art criticism or art history. Specialists in this field are skilled in using words to describe images. A common practice of many art historians is to reduce what may seem to be a very complex image to a few general shapes, colors and textures. An example of this is a description of Goya's "The 3rd of May 1808: The Execution of the Defenders of Madrid" (Fig. 1).
Figure 1
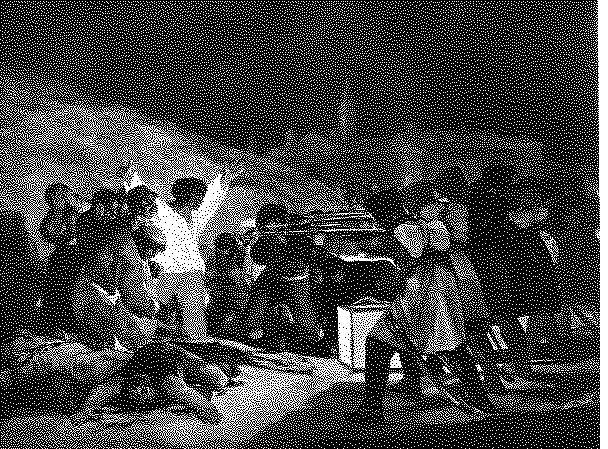
"Its organic structure, based on triangles and strong diagonals, is peculiarly fitting to the theme, and its neutral colors in grays and browns, with a splash of red in the pool of blood heightens its emotional impact." (Gardner, 1959, pg. 443)
One item to note from this description is the implication that these structural elements are arranged to produce an emotional impact and not a linguistic one. This underscores the dual-coding caveat of images being processed in the affective domain of cognition. This description is very brief and encapsulates hundreds of individual elements into gross generalizations. It is necessary to exclude lesser elements if we must focus on the dominant ones. It is interesting to note that even this brief description alludes to contextual elements of the "theme" and the "pool of blood" and is obviously formed as a caption intended to be read while viewing the painting. This underscores the difficulty in separating contextual elements from structural ones.
There are hundreds of individual structural elements including at least 22 people, 16 faces, all of their wearing apparel, weapons, the foreground elements, the city in the background and the dark night sky. That we can attribute meaning to the shapes and brush strokes alerts us to the fact that we are using contextual descriptions of structural elements. If we use entirely contextual descriptions Goya's painting becomes much simpler. We could describe it as an image consisting of three groups of people in front of a wall with a city in the background. Another description of the same work is presented to illustrate almost an entirely contextual description.
"Here the blazing color, broad fluid brush work, and dramatic nocturnal light are more emphatically Neo-Baroque than ever. The picture has all the emotional intensity of religious art, but these martyrs are dying for Liberty, not the kingdom of Heaven; and their executioners are not the agents of Satan but of political tyranny -- a formation of faceless automatons, impervious to their victims' despair and defiance. " (Janson, 1965, pg. 479)
It would seem to this researcher that Goya would support both this description and Gardner's earlier one because he chose structural elements and manipulated them in such a way that the later contextual description would be perceived. He chose to manipulate the structural elements of grays and browns so that the red pool of blood would be dominant. The two overlapping triangular shapes point like arrows toward the two dominant groups of people. We view the scene just an instant before the pure, bright white shirt of the rebel is to become crimson from the lines of the rifles pointing directly at it. In both examples stated above, the structural features of the image are tied directly to the contextual features. The artists have selected and arranged structural elements in such a masterful way that the desired context is effectively communicated to the observer. Another way to state this is that there is congruence between the structural dominance of the image and the contextual dominance that was the intent to communicate.
Based on the findings in the literature and translated into the terms of dominance, context, and congruency, the following hypothesis were adopted for this study.and which the methodology was designed to test.
http://silver.ucs.indiana.edu/~appelman/D_ONE.html
|
 |